

Distributed computing for efficient digital infrastructures

Today, distributed computing is an integral part of both our digital work life and private life. Anyone who goes online and performs a Google search is already using distributed computing. Distributed system architectures are also shaping many areas of business and providing countless services with ample computing and processing power. In the following, we will explain how this method works and introduce the system architectures used and its areas of application. We will also discuss the advantages of distributed computing.
What is distributed computing?
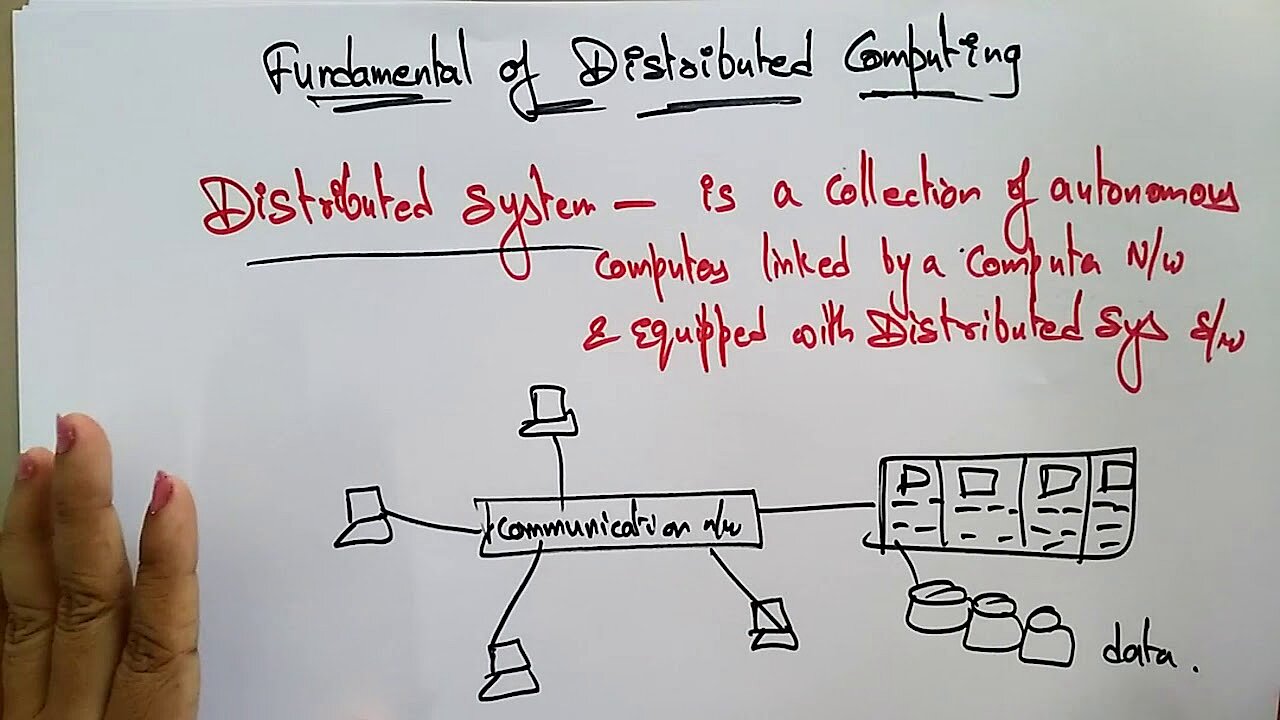
The term ‘distributed computing’ describes a digital infrastructure in which a network of computers solves pending computational tasks. Despite being physically separated, these autonomous computers work together closely in a process where the work is divvied up. The hardware being used is secondary to the method here. In addition to high-performance computers and workstations used by professionals, you can also integrate minicomputers and desktop computers used by private individuals.
Distributed hardware cannot use a shared memory due to being physically separated, so the participating computers exchange messages and data (e.g. computation results) over a network. This inter-machine communication occurs locally over an intranet (e.g. in a data centre) or across the country and world via the internet. Messages are transferred using internet protocols such as TCP/IP and UDP.
In line with the principle of transparency, distributed computing strives to present itself externally as a functional unit and to simplify the use of technology as much as possible. For example, users searching for a product in the database of an online shop perceive the shopping experience as a single process and do not have to deal with the modular system architecture being used.
In short, distributed computing is a combination of task distribution and coordinated interactions. The goal is to make task management as efficient as possible and to find practical flexible solutions.
How does distributed computing work?
In distributed computing, a computation starts with a special problem-solving strategy. A single problem is divided up and each part is processed by one of the computing units. Distributed applications running on all the machines in the computer network handle the operational execution.
Distributed applications often use a client-server architecture. Clients and servers share the work and cover certain application functions with the software installed on them. A product search is carried out using the following steps: The client acts as an input instance and a user interface that receives the user request and processes it so that it can be sent on to a server. The remote server then carries out the main part of the search function and searches a database. The search results are prepared on the server-side to be sent back to the client and are communicated to the client over the network. In the end, the results are displayed on the user’s screen.
Middleware services are often integrated into distributed processes. Acting as a special software layer, middleware defines the (logical) interaction patterns between partners and ensures communication, and optimal integration in distributed systems. It provides interfaces and services that bridge gaps between different applications and enables and monitors their communication (e.g. through communication controllers). For operational implementation, middleware provides a proven method for cross-device inter-process communication called remote procedure call (RPC) which is frequently used in client-server architecture for product searches involving database queries.
This integration function, which is in line with the transparency principle, can also be viewed as a translation task. Technically heterogeneous application systems and platforms normally cannot communicate with one another. Middleware helps them to “speak one language” and work together productively. In addition to cross-device and cross-platform interaction, middleware also handles other tasks like data management. It controls distributed applications’ access to functions and processes of operating systems that are available locally on the connected computer.


 To display this video, third-party cookies are required. You can access and change your cookie settings here.
To display this video, third-party cookies are required. You can access and change your cookie settings here. What are the different types of distributed computing?
Distributed computing is a multifaceted field with infrastructures that can vary widely. It is thus nearly impossible to define all types of distributed computing. However, this field of computer science is commonly divided into three subfields:
- cloud computing
- grid computing
- cluster computing
Cloud computing uses distributed computing to provide customers with highly scalable cost-effective infrastructures and platforms. Cloud providers usually offer their resources through hosted services that can be used over the internet. A number of different service models have established themselves on the market:
- Software as a service (SaaS): In the case of SaaS, the customer uses the cloud provider’s applications and associated infrastructure (e.g. servers, online storage, computing power). The applications can be accessed with a variety of devices via a thin client interface (e.g. a browser-based web app). Maintenance and administration of the outsourced infrastructure is handled by the cloud provider.
- Platform as a service (PaaS): In the case of PaaS, a cloud-based environment is provided (e.g. for developing web applications). The customer retains control over the applications provided and can configure customized user settings while the technical infrastructure for distributed computing is handled by the cloud provider.
- Infrastructure as a service (IaaS): In the case of IaaS, the cloud provider supplies a technical infrastructure which users can access via public or private networks. The provided infrastructure may include the following components: servers, computing and networking resources, communication devices (e.g. routers, switches, and firewalls), storage space, and systems for archiving and securing data. As for the customer, they retain control over operating systems and provided applications.
Grid computing is based on the idea of a supercomputer with enormous computing power. However, computing tasks are performed by many instances rather than just one. Servers and computers can thus perform different tasks independently of one another. Grid computing can access resources in a very flexible manner when performing tasks. Normally, participants will allocate specific resources to an entire project at night when the technical infrastructure tends to be less heavily used.
One advantage of this is that highly powerful systems can be quickly used and the computing power can be scaled as needed. There is no need to replace or upgrade an expensive supercomputer with another pricey one to improve performance.
Since grid computing can create a virtual supercomputer from a cluster of loosely interconnected computers, it is specialized in solving problems that are particularly computationally intensive. This method is often used for ambitious scientific projects and decrypting cryptographic codes.
Cluster computing cannot be clearly differentiated from cloud and grid computing. It is a more general approach and refers to all the ways in which individual computers and their computing power can be combined together in clusters. Examples of this include server clusters, clusters in big data and in cloud environments, database clusters, and application clusters. Computer networks are also increasingly being used in high-performance computing which can solve particularly demanding computing problems.
Different types of distributed computing can also be defined by looking at the system architectures and interaction models of a distributed infrastructure. Due to the complex system architectures in distributed computing, the term distributed systems is more often used.
The following are some of the more commonly used architecture models in distributed computing:
- client-server model
- peer-to-peer model
- multilayered model (multi-tier architectures)
- service-oriented architecture (SOA)
The client-server model is a simple interaction and communication model in distributed computing. In this model, a server receives a request from a client, performs the necessary processing procedures, and sends back a response (e.g. a message, data, computational results).
A peer-to-peer architecture organizes interaction and communication in distributed computing in a decentralized manner. All computers (also referred to as nodes) have the same rights and perform the same tasks and functions in the network. Each computer is thus able to act as both a client and a server. One example of peer-to-peer architecture is cryptocurrency blockchains.
When designing a multilayered architecture, individual components of a software system are distributed across multiple layers (or tiers), thus increasing the efficiency and flexibility offered by distributed computing. This system architecture can be designed as two-tier, three-tier or n-tier architecture depending on its intended use and is often found in web applications.


A service-oriented architecture (SOA) focuses on services and is geared towards addressing the individual needs and processes of company. This allows individual services to be combined into a bespoke business process. For example, an SOA can cover the entire process of “ordering online” which involves the following services: “taking the order”, “credit checks” and “sending the invoice”. Technical components (e.g. servers, databases, etc.) are used as tools but are not the main focus here. In this type of distributed computing, priority is given to ensuring that services are effectively combined, work together well, and are smartly organized with the aim of making business processes as efficient and smooth as possible.
In a service-oriented architecture, extra emphasis is placed on well-defined interfaces that functionally connect the components and increase efficiency. These can also benefit from the system’s flexibility since services can be used in a number of ways in different contexts and reused in business processes. Service-oriented architectures using distributed computing are often based on web services. They are implemented on distributed platforms, such as CORBA, MQSeries, and J2EE.
 To display this video, third-party cookies are required. You can access and change your cookie settings here.
To display this video, third-party cookies are required. You can access and change your cookie settings here. The advantages of distributed computing
Distributed computing has many advantages. It allows companies to build an affordable high-performance infrastructure using inexpensive off-the-shelf computers with microprocessors instead of extremely expensive mainframes. Large clusters can even outperform individual supercomputers and handle high-performance computing tasks that are complex and computationally intensive.
Since distributed computing system architectures are comprised of multiple (sometimes redundant) components, it is easier to compensate for the failure of individual components (i.e. increased partition tolerance). Thanks to the high level of task distribution, processes can be outsourced and the computing load can be shared (i.e. load balancing).
Many distributed computing solutions aim to increase flexibility which also usually increases efficiency and cost-effectiveness. To solve specific problems, specialized platforms such as database servers can be integrated. For example, SOA architectures can be used in business fields to create bespoke solutions for optimizing specific business processes. Providers can offer computing resources and infrastructures worldwide, which makes cloud-based work possible. This allows companies to respond to customer demands with scaled and needs-based offers and prices.
Distributed computing’s flexibility also means that temporary idle capacity can be used for particularly ambitious projects. Users and companies can also be flexible in their hardware purchases since they are not restricted to a single manufacturer.
Another major advantage is its scalability. Companies are able to scale quickly and at a moment’s notice or gradually adjust the required computing power to the demand as they grow organically. If you choose to use your own hardware for scaling, you can steadily expand your device fleet in affordable increments.
Despite its many advantages, distributed computing also has some disadvantages, such as the higher cost of implementing and maintaining a complex system architecture. In addition, there are timing and synchronization problems between distributed instances that must be addressed. In terms of partition tolerance, the decentralized approach does have certain advantages over a single processing instance. However, the distributed computing method also gives rise to security problems, such as how data becomes vulnerable to sabotage and hacking when transferred over public networks. Distributed infrastructures are also generally more error-prone since there are more interfaces and potential sources for error at the hardware and software level. Problem and error troubleshooting is also made more difficult by the infrastructure’s complexity.
What is distributed computing used for?
Distributed computing has become an essential basic technology involved in the digitalization of both our private life and work life. The internet and the services it offers would not be possible if it were not for the client-server architectures of distributed systems. Every Google search involves distributed computing with supplier instances around the world working together to generate matching search results. Google Maps and Google Earth also leverage distributed computing for their services.
Distributed computing methods and architectures are also used in email and conferencing systems, airline and hotel reservation systems as well as libraries and navigation systems. In the working world, the primary applications of this technology include automation processes as well as planning, production, and design systems. Social networks, mobile systems, online banking, and online gaming (e.g. multiplayer systems) also use efficient distributed systems.
Additional areas of application for distributed computing include e-learning platforms, artificial intelligence, and e-commerce. Purchases and orders made in online shops are usually carried out by distributed systems. In meteorology, sensor and monitoring systems rely on the computing power of distributed systems to forecast natural disasters. Many digital applications today are based on distributed databases.
Particularly computationally intensive research projects that used to require the use of expensive supercomputers (e.g. the Cray computer) can now be conducted with more cost-effective distributed systems. The volunteer computing project SETI@home has been setting standards in the field of distributed computing since 1999 and still are today in 2020. Countless networked home computers belonging to private individuals have been used to evaluate data from the Arecibo Observatory radio telescope in Puerto Rico and support the University of California, Berkeley in its search for extraterrestrial life.
A unique feature of this project was its resource-saving approach. The analysis software only worked during periods when the user’s computer had nothing to do. After the signal was analyzed, the results were sent back to the headquarters in Berkeley.
On the YouTube channel Education 4u, you can find multiple educational videos that go over the basics of distributed computing.